TL;DR
- 本文解決: 把自己的卡通形象訓成 Wan 2.2 i2v LoRA,再變成 scroll-aware 動畫掛上個人形象網站
- 推薦給: 想用自己訓練的 character LoRA 做動畫的個人品牌經營者、踩過 musubi-tuner 在 Windows + 4070 12GB 雷的人
- 讀完你會知道: 為什麼 LoRA「看起來訓壞」其實是 lightx2v 加速 LoRA 蓋過效果;Windows 上 musubi-tuner 的 8 個地雷與修法;i2v 角色一致性靠的不是 LoRA 是起始圖;用 IntersectionObserver 在 Astro 站把影片按 scroll 切換的最小可行做法
📌 目錄
🎮 事情怎麼開始:本來只是 LoL 開不起來
2026-05-09 晚上想開 League of Legends 放鬆,跳出 VAN-57。10 分鐘以為能解決,結果開機連續 5 次 BSOD,bugcheck 都是 0x1E 或 0x3B,dump 裡有 vgk.sys(Riot Vanguard kernel driver)。
修了一晚最後找到的 root cause 不單純:
- ✅ TPM 2.0 / Secure Boot / UEFI 都在
- ✅ 不是 Intel 13/14 代電壓問題(我是 AMD)
- ❌ GIGABYTE Control Center 的
gdrv3.sys+MsIo64.sys+iocbios2.sys三個主機板 kernel driver 跟新版 BIOS + Vanguard 在 fp8 / state_dict swap 路徑上鬥到爆
sc stop vgc
sc stop vgk
sc delete vgc
sc delete vgk
rmdir /S /Q "C:\Program Files\Riot Vanguard"加上停掉 Razer driver、BIOS Load Defaults。重點是:清掉 Vanguard 之後 GPU 跑滿載 8 小時沒事。
LoL 不能玩了,那就拿這台 GPU 訓 LoRA 吧。
---
🧪 Wan 2.2 i2v LoRA 在 4070 12GB 上的 8 個地雷
訓練配置:Wan 2.2 i2v-A14B + musubi-tuner + RTX 4070 12GB + Windows 11 + 40 張角色訓練圖。我是個跑了 19 次失敗 才讓 step counter 真的前進的人。每一次失敗都是 Windows + musubi-tuner 邊角的一個地雷。
⚠️ 雷區清單
| # | 錯誤 | 根因 | 修法 |
|---|---|---|---|
| 1 | 'video/h264-mp4' is not a valid VideoContainer | ComfyUI SaveVideo node 改名 | format mp4 + codec h264 |
| 2 | Unexpected key(s) "scaled_fp8"... | DiT 本身是 pre-scaled fp8 | 加 --fp8_scaled flag |
| 3 | DiT weights is already in fp8 format | 用 ComfyUI 推論版 fp8 model 訓練 | 改用純 bf16 27GB DiT 版本 |
| 4 | 'cp950' codec can't encode '数' | musubi-tuner 寫死日文 print,Windows 中文 console 不認 | 修源碼 wan_train_network.py 第 1 行 wrap stdout 為 UTF-8 |
| 5 | KeyError: 'latents_image' | i2v 需要 cache image latents | wan_cache_latents.py 加 --i2v |
| 6 | DataLoader hang 死在 step 0 | Windows + PyTorch DataLoader 多 worker 死鎖 | --max_data_loader_n_workers 0 |
| 7 | TypeError: 'Tensor' object is not iterable 在 step 71 | musubi-tuner 在 fp8 + dual DiT swap 時 bug | 拿掉 --dit_high_noise,只訓 low_noise |
| 8 | 訓練到 step 375 後 exit 3221225477 (ACCESS VIOLATION) | bitsandbytes adamw8bit 在 Windows 累積記憶體洩漏 | --optimizer_type adamw(純 PyTorch) |
🔥 wan_train_network.py 開頭 UTF-8 救命 patch
musubi-tuner 在 accelerator.print 寫日文,Windows 中文系統 (cp950) 直接炸:
import sys
import io
try:
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8', errors='replace', line_buffering=True)
sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8', errors='replace', line_buffering=True)
except Exception:
pass加在 src/musubi_tuner/wan_train_network.py 第 1 行(任何 import 之前),日文 print 變成 ? 但不會崩 — 比設環境變數 PYTHONIOENCODING 可靠(環境變數對 accelerate spawn 出的 subprocess 不一定 cascade 過去)。
🛠️ 最終 working .bat(給你直接抄)
@echo off
cd /d D:\ai-tools\musubi-tuner
set PYTHONIOENCODING=utf-8
set PYTHONUTF8=1
accelerate launch --num_cpu_threads_per_process 1 --mixed_precision bf16 ^
src/musubi_tuner/wan_train_network.py ^
--task i2v-A14B ^
--dit D:/ai-tools/musubi-tuner/models/wan2.2_i2v_low_noise_14B_bf16.safetensors ^
--vae D:/ai-tools/ComfyUI/models/vae/wan_2.1_vae.safetensors ^
--t5 D:/ai-tools/musubi-tuner/models/models_t5_umt5-xxl-enc-bf16.pth ^
--dataset_config training_data/ohwx_character/dataset.toml ^
--sdpa --mixed_precision bf16 --fp8_base --fp8_scaled ^
--blocks_to_swap 35 ^
--max_data_loader_n_workers 0 ^
--optimizer_type adamw --learning_rate 1e-4 --gradient_checkpointing ^
--network_module musubi_tuner.networks.lora_wan ^
--network_dim 20 --network_alpha 10 ^
--timestep_sampling shift --discrete_flow_shift 5.0 ^
--max_train_epochs 8 --save_every_n_epochs 2 --save_every_n_steps 100 --seed 42 ^
--output_dir output/ohwx_character_v3 ^
--output_name ohwx_character_wan22_v3
8 epoch × 120 step/epoch = 960 step,在 4070 12GB 上 1 小時 28 分跑完,loss 從 0.00208 降到 0.000469(4.4 倍下降)。
---
🔍 LoRA 看起來訓壞了?兇手是 lightx2v 加速 LoRA
訓完拿 LoRA 去 ComfyUI 出第一支影片,臉完全跑掉。原本 ohwx 是這個(窄臉、銳利眼、smirk 露牙):

實際生出來:
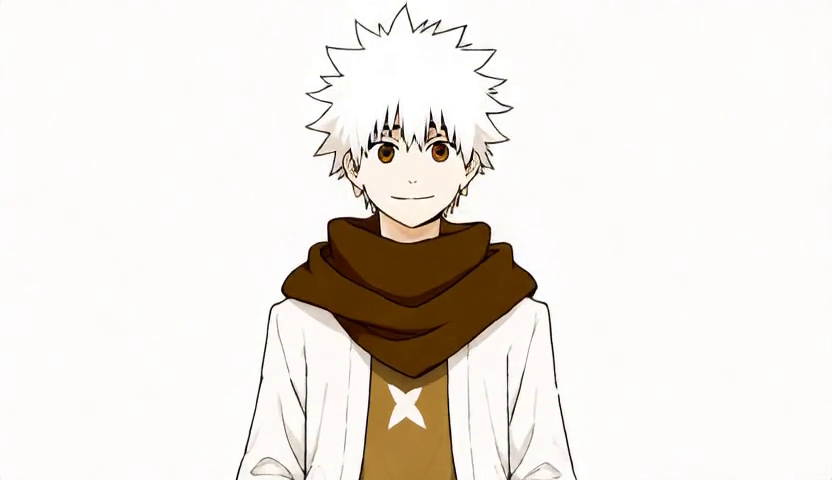
完全不同人。一度懷疑 LoRA 訓壞,準備重訓 v4。
但事實上是 lightx2v 4-step 加速 LoRA 把我的角色 LoRA 蓋掉了。
lightx2v 的工作原理是 distill:把 Wan 30 step 壓到 4 step。問題在它的 distill 訓練集偏向 chibi / kawaii 風格 → 你的角色 LoRA 哪怕 strength 拉到 2.0 也敵不過它(lightx2v 強度 1.0 已經把模型整個 shift 過去)。
驗證方法:完全拿掉 lightx2v,跑 30 step 純 sampling。同一個起始圖、同一個 LoRA、同一個 prompt,臉就回來了:
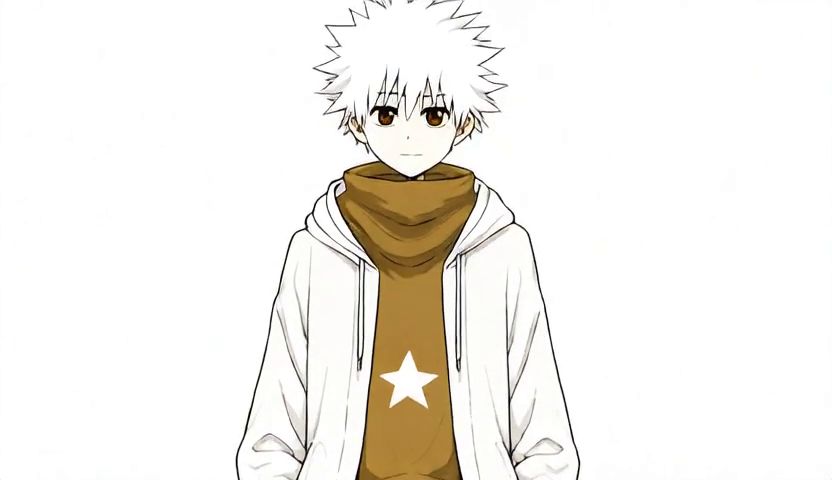
眉毛重新變銳利、眼睛變細、年齡感對了。
🧠 為什麼這個雷一定要踩才會懂
社群討論 (Wan2.2-Lightning #5: bad motion):很多人也發現 lightx2v 「動作 / 風格被壓平」。但你如果同時用 character LoRA,會以為是 character LoRA 訓壞了。
規則: 加速 LoRA 跟 character LoRA 都用 strength 1.0 = 你以為兩個各佔一半,實際上加速 LoRA 蓋過 character LoRA。
---
🎯 i2v 角色一致性的真正關鍵:起始圖
去掉 lightx2v 之後,臉對了,但用「身體起始圖」(body_01.png 全身正面站姿)出來的影片,臉部還是 base model 自由發揮。
| 起始圖 | 結果 |
|---|---|
| body_01(全身、頭很小) | 臉是 base model 隨機產生 |
| head_07(半身、臉清楚) | 整段 49 frame 都保持 ohwx 真實臉 |
⚖️ 解析度比例也決定臉會不會被切掉
832×480 是 ComfyUI 預設寬螢幕 16:9,但你 body 訓練圖是直幅人物 → ComfyUI 自動裁切,整段 3 秒影片角色頭都看不到。
改成 480×832 直幅,匹配訓練圖比例 → 全身入鏡:

---
⚡ 動作不出來怎麼辦:CFG、step、解析度三件套
第一批用 lightx2v 4 step 出的影片角色幾乎不動(鏡頭緩慢平移而已),不是因為 i2v 學不會,是因為:
| 參數 | 4-step 加速 | 30-step 正常 |
|---|---|---|
| step 數 | 4 | 30 |
| CFG | 1.0(lightx2v 規定) | 5.0 |
| 模型有時間規劃動作? | ✗ | ✓ |
| 模型聽 prompt? | △ | ✓ |
| 用時 (4070, 480×832×49 frame) | ~5 min | ~14 min |
🎬 動作 prompt 寫法
| ❌ 沒用 | ✅ 有用 |
|---|---|
ohwx_character looking at viewer | ohwx_character waving right hand at camera energetically, big friendly smile, slight bounce |
ohwx_character (空白) | ohwx_character sitting on chair, reading a book, turning the page, hand moving across the page |
slight head movement 這種輕描淡寫,模型真的會幫你只動一點點。
Negative prompt 加:static image, frozen, no motion — 把「不動」往負方向推。
---
🧩 整合進形象網站:CharacterCompanion + IntersectionObserver
我這個站是 Astro 6 + React 19 + Tailwind 4 + Firebase,要把角色變成 scroll-aware:滑到 Hero 揮手、滑到 Skills 區思考、滑到 FAQ 攤手解釋。

🛠️ 兩步整合:data anchor + 一個 React 元件
第一步:給每個 section 一個 data-companion-section 屬性:
<section data-companion-section="hero" class="...">...</section>
<section data-companion-section="latest" class="...">...</section>
<section data-companion-section="about" class="...">...</section>
<!-- 等等 -->第二步:寫一個浮動 React 元件(簡化版):
import { useEffect, useRef, useState } from 'react';
const BASE = (import.meta.env.BASE_URL || '/').replace(/\/$/, '');
const v = (file: string) => ${BASE}/character/${file};
const SECTION_VIDEOS = {
hero: { src: v('hero_wave.mp4'), label: '揮手' },
latest: { src: v('latest_reading.mp4'), label: '翻書' },
about: { src: v('about_nod.mp4'), label: '點頭' },
production: { src: v('production_point.mp4'), label: '介紹' },
skills: { src: v('skills_think.mp4'), label: '思考' },
findme: { src: v('findme_invite.mp4'), label: '招手' },
faq: { src: v('faq_explain.mp4'), label: '解釋' },
};
export default function CharacterCompanion() {
const [section, setSection] = useState('hero');
const videoRef = useRef<HTMLVideoElement | null>(null);
useEffect(() => {
const anchors = document.querySelectorAll<HTMLElement>('[data-companion-section]');
const visible = new Map<HTMLElement, number>();
const observer = new IntersectionObserver((entries) => {
for (const e of entries) {
if (e.isIntersecting) visible.set(e.target as HTMLElement, e.intersectionRatio);
else visible.delete(e.target as HTMLElement);
}
let best: HTMLElement | null = null, bestRatio = 0;
visible.forEach((ratio, el) => { if (ratio > bestRatio) { bestRatio = ratio; best = el; } });
if (best) setSection((best as HTMLElement).dataset.companionSection!);
}, { threshold: [0, 0.25, 0.5, 0.75, 1] });
anchors.forEach((a) => observer.observe(a));
return () => observer.disconnect();
}, []);
useEffect(() => {
const vEl = videoRef.current;
if (!vEl) return;
const target = SECTION_VIDEOS[section]?.src;
if (!target || vEl.src.endsWith(target)) return;
vEl.src = target;
vEl.load();
vEl.play().catch(() => {});
}, [section]);
return (
<div className="fixed bottom-4 right-4 z-50" style={{ width: 'clamp(140px, 18vw, 220px)' }}>
<video ref={videoRef} autoPlay loop muted playsInline
className="block w-full h-auto border-2 border-black"
style={{ boxShadow: '4px 4px 0 #0a0a0a' }}
src={SECTION_VIDEOS[section]?.src} />
</div>
);
}
掛載:
<CharacterCompanion client:idle />🐛 踩到的坑:Astro base URL
我站是 GitHub Pages project page,base URL 是 /ai-lecturer-bob。第一版我元件寫死 /character/hero_wave.mp4,瀏覽器永遠 404。所有 public assets 引用都要過 import.meta.env.BASE_URL:
// ❌ WRONG: 404 in production
const src = '/character/hero_wave.mp4';
// ✅ CORRECT: works in dev and prod
const BASE = (import.meta.env.BASE_URL || '/').replace(/\/$/, '');
const src = ${BASE}/character/hero_wave.mp4;
🎨 視覺成果
8 個 section 對應 8 個動作:



---
✅ 完整 working 配方(給未來自己跟讀者)
從 0 開始要做什麼。前置需求:
| 項目 | 用途 | 怎麼裝 / 確認 |
|---|---|---|
| Python 3.11 | 跑 musubi-tuner | python --version |
| RTX 4070 12GB+ | 訓練 + 推論 GPU | nvidia-smi 看到 |
| CUDA 12.4+ + PyTorch 2.7+ | 對應 fp8 + bf16 | python -c "import torch; print(torch.cuda.is_available())" |
| musubi-tuner | 訓練框架 | git clone https://github.com/kohya-ss/musubi-tuner && cd musubi-tuner && pip install -e . |
| ComfyUI | 推論 + workflow | git clone https://github.com/comfyanonymous/ComfyUI |
| Wan 2.2 bf16 weights | 訓練必須是 bf16 | 從 HF 下載 wan2.2_i2v_*_14B_bf16.safetensors(27GB × 2) |
| 訓練圖 30-40 張 | 角色 LoRA | 自己畫或委託,1024px+,多角度多姿勢 |
三件套指令(從訓練圖到上站)
:: 1. Cache(一次性)
python wan_cache_latents.py --dataset_config training_data/ohwx_character/dataset.toml ^
--vae ComfyUI/models/vae/wan_2.1_vae.safetensors --i2v
python wan_cache_text_encoder_outputs.py --dataset_config training_data/ohwx_character/dataset.toml ^
--t5 models/models_t5_umt5-xxl-enc-bf16.pth --batch_size 1
:: 2. 訓練(用上面的 .bat,約 1.5 小時)
train_ohwx_v3.bat
:: 3. 推論(ComfyUI workflow,每支影片 14 分鐘)
:: workflow 在站內 repo: ai-lecturer-bob-fresh/scripts/workflows/wan22_i2v_ohwx.json
驗證指令
:: 訓練 LoRA 存在
dir output\ohwx_character_v3\*.safetensors
:: ComfyUI 認得這個 LoRA
curl http://127.0.0.1:8188/object_info/LoraLoaderModelOnly | findstr ohwx
如果 ComfyUI 出來臉是 chibi 大眼 = 沒拿掉 lightx2v。
如果影片整段不動 = 沒改 cfg、沒加 negative prompt「static」、step 太少。
---
⏱️ 心法 / 時間成本拆解
24 小時內走完的流程:
| 階段 | 時間 | 產出 |
|---|---|---|
| BSOD 修復 + 系統穩定 | 2 小時 | Vanguard 移除、Razer 停用、系統 8 小時不藍屏 |
| LoRA 訓練 19 次失敗找雷區 | 4 小時 | working .bat |
| 真正訓練跑完 | 1.5 小時 | 13 個 checkpoint,loss 0.000469 |
| ComfyUI 19 次測試找 LoRA + i2v 配方 | 4 小時 | 確認 head 起始 + 30 step + 480×832 直幅 |
| 7 支 section 影片產出 | 1.5 小時 | hero / about / production / skills / findme / faq / reading / walking |
CharacterCompanion 元件 + Astro 整合 | 30 分鐘 | scroll-aware 浮動角色 |
如果有人說「我訓出來不像」就準備丟掉重訓 → 先把推論配方做 ablation(拿掉 lightx2v、換起始圖、換 cfg),通常找到的不是模型問題。
---
❓ 常見問題
Wan 2.2 i2v 跟 Wan 2.1 i2v 差在哪?我訓 2.2 的 LoRA 能用在 2.1 嗎?
不能。Wan 2.2 i2v 是 dual-DiT 設計(high-noise + low-noise 兩個 DiT),patch_embedding 是 36 通道(16 video + 20 image control),Wan 2.1 i2v 是單 DiT 16 通道。LoRA 維度跟 base model 綁死,跨版本不相容。
4070 12GB 真的能訓 14B i2v?要花多久?
可以,但必須用 --blocks_to_swap 35(40 個 block 中 35 個換到 CPU)+ --fp8_base --fp8_scaled + --gradient_checkpointing。8 epoch / 120 step per epoch = 960 step,約 1 小時 28 分。VRAM 用 9-10GB,CPU RAM 用 23GB。記憶體不夠就降到 32GB RAM 不行,建議 64GB。
為什麼選 i2v 不選 t2v 或 Flux 靜態圖 LoRA?
i2v 角色一致性靠起始圖鎖死 = 不用擔心 LoRA 訓得不夠強。靜態圖 LoRA(Flux、SDXL)要 dim ≥ 32 + 大量訓練步數才能讓 trigger word 吸收角色特徵,且生不出動畫。我的目標是「在網站上會動的代表角色」,i2v 是直球解。
訓練踩過最大的坑是什麼?一句話總結。
--max_data_loader_n_workers 0 — Windows + PyTorch DataLoader 多 worker 在 Wan 2.2 i2v + fp8 配置下會 hang 在 step 0,CPU 不轉、GPU 也不算,看起來像系統卡死。設成 0(主執行緒讀資料)就解。社群很少人提這個。
為什麼影片要做成 scroll-aware 不是固定播一支?
固定一支影片放久了會疲勞、變裝飾。Scroll-aware 讓角色「跟著讀者的閱讀位置演戲」 — 在 Hero 揮手歡迎、在 Skills 區思考、在 FAQ 攤手解釋 — 變成內容的一部分而不是 banner。實作只多 30 行 IntersectionObserver 代碼。
---
🔗 延伸資源
- musubi-tuner GitHub repo(kohya-ss) — Wan 2.2 / Hunyuan / FLUX LoRA 訓練主要框架
- ComfyUI — 推論用的 node-based UI
- lightx2v Wan 2.2 Lightning — 4-step 加速 LoRA,但會蓋掉 character LoRA
- Wan 2.2 i2v 訓練官方文檔(musubi-tuner/docs/wan.md) — base 配置出處
- Wan2.2 i2v-A14B LoRA training has no effect (issue #621) — 社群討論 LoRA 沒效果的多種原因
- 本站相關文章:RTX 4070 Wan 2.2 I2V 訓練 loop — 同主題的前一版踩坑記錄
不怕死,只怕不過癮。